[액션파워 LAB] 트랜스포머(Transformer) 알아보기
이번 기술 블로그에서는 최근 Large Language Model (LLM)과 더불어 이미지 분야, 시계열 분야 등, 다양한 도메인에서 backbone 모델로써 가장 많이 활용되는 트랜스포머 모델에 대해서 알아보고자 합니다.

트랜스포머(Transformer)
트랜스포머는 2017년도 구글에서 발표한 “Attention is all you need”[1] 라는 논문에서 최초로 공개된 모델입니다. 해당 모델은 기존의 Recurrent Neural Network (RNN)이나 Convolution Neural Network (CNN)의 기반의 모델을 탈피하고, Attention 기반의 모델 구성을 통하여 자연어 처리 분야에서 좋은 성능을 기록하였습니다.

트랜스포머의 모델 구성을 위의 이미지와 같습니다. 해당 모델에서 대해 다음과 같은 4가지 모듈에 대해서 분석하고자 합니다.
- Positional Encoding
- Multi-head Self-Attention in Encoder
- Masked Multi-head Self-Attention in Decoder
- Multi-head Self-Attention in Decoder
- FeedForward Network
위의 3가지에 대해서 하나씩 알아보고자 합니다.
1. Positional Encoding (PE)

트랜스포머는 RNN과 다르게 글을 한번에 읽을 수 있도록 구현한 모델입니다. 따라서 우리는 모델에게 단어의 위치 정보를 알려줄 필요가 있습니다. 이때 PE를 활용하여 각각의 위치정보를 입력해 줍니다.
위 그림에서
(a) 는 PE를 이용하지 않아 철수와 영희의 위치가 변경되었지만 값은 동일
(b) 는 PE를 이용하여 철수와 영희가 위치가 변경되면 값도 변경 에 대한 결과를 나타냅니다.
2. Multi-head Self-Attention in Encoder
트랜스포머 모델의 핵심 내용을 말하라고 하면 해당 모듈을 설명하면 될 정도로 가장 큰 역할을 담당하고 있는 부분입니다.
그럼 Self-Attention이 담당하고 있는 역할은 무엇일까요?

Self-Attention의 역할은 위의 이미지로 이해할 수 있습니다. 해당 이미지에서 “animal”이 “it”과 진한색의 색으로 연결되어 있는 것을 볼 수 있습니다.
입력 문장을 해석해보면 “동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다.” 입니다. 여기서 “그것”에 해당하는 것은 사람은 쉽게 동물이라는 것을 알 수 있지만 기계는 그렇지 못합니다. Self-Attention의 역할은 입력 문장에서 단어들끼리의 유사도를 이용하여 가장 연관성이 높은 단어를 찾아 내는 것이라고 할 수 있습니다.
따라서 트랜스포머의 통하여 문맥의 정보를 포함한 단어 벡터인 Contextualized Word Embedding Vector를 얻어낼 수 있습니다.
의미론적으로는 Self-Attention이 하는 역할을 다음과 같이 알아봤습니다. 그럼 해당 모듈은 어떻게 연산이 되는 걸까요?
Step1 : Query, Key, Value matrix 생성
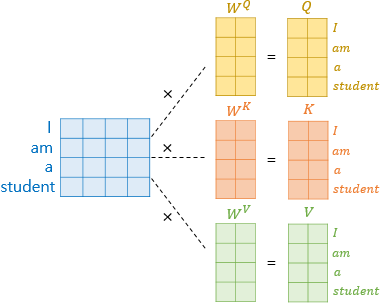
처음에 단어의 임베딩과 PE를 더한 벡터를 각각의 Query, Key, Value에 해당하는 weight matrix와 연산을 통하여 $Q, K, V$의 값을 얻어냅니다.
Step2 : Attention Value 생성
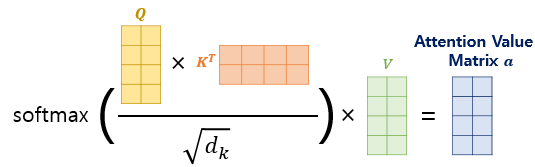
이후 $Q$와 $K$를 통하여 Attention 값을 얻어낸 뒤 $V$를 곱하여 최종 출력 벡터를 얻어냅니다. 다음을 수식으로 나타내면 다음과 같습니다.
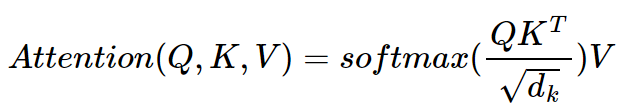
해당 수식에서 $\sqrt{d_k}$ 는 scaling을 의미합니다. Scaling을 진행하는 이유는 $QK^T$의 결과에서 특정 값이 너무 클 경우 학습이 균일하게 되지 않고, 하나에 집중되어 학습되어 성능에 악영향을 주는 것을 방지하기 위해서 이용합니다.
Step3 : Residual Connection
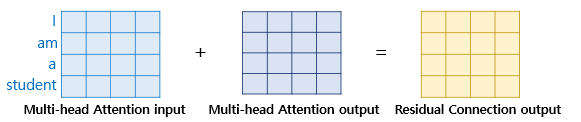
Self-Attention의 결과를 해당 연산을 진행하기 전의 입력 값과 더한 뒤 LayerNormalization을 이용하여 최종 출력을 얻어 낼 수 있습니다.
3. Masked Multi-head Attention in Decoder
Masked Multi-head Attention은 decoder에만 존재하는 모듈로 RNN의 연산 룰을 지니고 있습니다. Encoder에 있는 Multi-head Attention의 경우, Self-Attention 연산시에 모든 단어들과의 연관성에 대해서 연산을 진행합니다. 그렇기 때문에 위 모듈은 Bi-directional(양방향성) 하다고 합니다.
하지만, Decoder의 경우는 문장을 생성하거나, 정답을 도출하는 부분으로써, RNN 과 동일하게 순차적으로 데이터를 읽어올 수 있으며, 앞에 생성될 단어는 뒤의 단어를 볼 수 없도록 구현하며, Uni-directional(단방향성)을 가집니다.
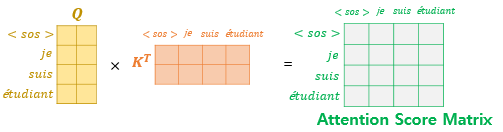
따라서 앞의 등장하는 단어가 뒤에 단어를 보지 못하게 Masking 이라는 작업을 진행하게 됩니다.
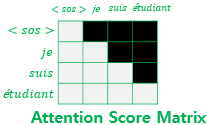
Masking은 Q, K의 곱 연산을 한 matrix에서 진행하며, 위의 이미지처럼 진행합니다.
위 이미지를 해석하면 첫번째 등장하는 단어는 첫번째 단어만 볼 수 있으며, 두번째 등장하는 단어는 첫번째와 두번째, 세번째 등장하는 단어는 첫번째, 두번째, 세번째, …… 와 같이 이후에 등장하는 단어는 볼 수 없도록 matrix에 Masking 작업을 진행합니다. 위 이미지에서 검은색으로 된 부분이 Masking을 의미합니다.
4. Multi-head Attention in Decoder
Decoder에 존재하는 Multi-head Attention은 Encoder에 존재하는 것과 차이점이 무엇일까요?
연산적인 부분에서 두개의 차이점은 존재하지 않습니다. 유일한 차이점은 입력 데이터인데요.
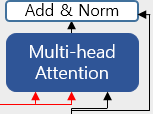
빨간색 선은 Encoder로 부터 얻은 값을 의미하며, 검은색 선은 Decoder로 부터 얻은 값을 의미합니다. 즉, Self-Attention을 진행하기 위한 Q, K, V에서 Q, K는 Encoder의 출력으로부터 값을 가져오고, V는 Decoder로부터 값을 가져옵니다.
해당 연산을 통하여 Encoder에서 얻은 정보를 Decoder로 넘겨주는 역할을 진행합니다.
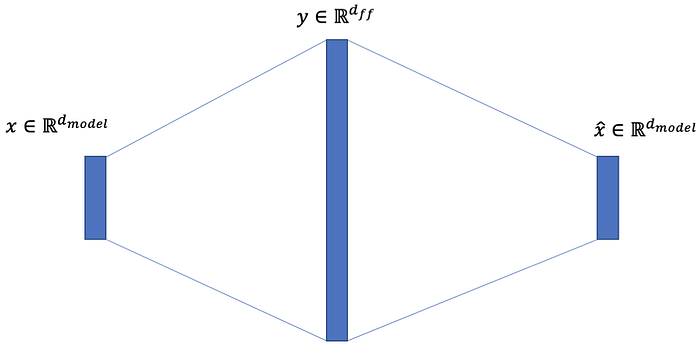
5. FeedForward Network
FeedForwardNetwork는 2층으로 된 linear projection layer이며, 단순 MLP 연산과 동일합니다. 일반적으로 MLP 연산의 차원은 입력 차원의 4배를 이용합니다.
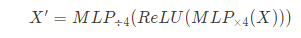
결론
이번엔 트랜스포머의 모델 구조에 대해서 알아보았습니다. 다시 정리를 하면 트랜스포머는 RNN이나 CNN을 이용하지 않고 Attention으로만 구현된 모델입니다. 또한 모든 단어들과의 연관성을 분석하여 언어적인 특성을 학습하여 문맥에 맞는 단어 임베딩을 얻어내어 추후의 다양한 downstream task들에서 좋은 성능을 보이고 있습니다.
추가적으로 트랜스포머를 이용한 초기 자연어 모델은 트랜스포머의 Decoder를 이용한 GPT-1과 Encoder를 이용한 BERT가 있습니다. 트랜스포머가 자연어 모델에 어떻게 쓰이며, LLM이 나오기 이전에 언어모델들이 궁금하신 분들이면 해당 자료를 추가로 찾아보시면 좋을 것 같습니다.
이번 자료가 트랜스포머를 처음 공부하시는 분들에게 모델의 구성방식과 이유에 대해서 알아가는 시간이 되셨으면 좋겠습니다 감사합니다.
추가자료
Transformer 모델 구성 코드
Pytorch from scratch : https://github.com/bentrevett/pytorch-seq2seq
Module in pytorch library : https://pytorch.org/docs/stable/generated/torch.nn.Transformer.html
Reference
[1] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
